
授权公布号:CN116362223B
一种网页文章标题和正文的自动识别方法及装置
有效
申请
2023-03-07
申请公布
2023-06-30
授权
2023-12-15
预估到期
2043-03-07
| 申请号 | CN202310211865.1 |
| 申请日 | 2023-03-07 |
| 申请公布号 | CN116362223A |
| 申请公布日 | 2023-06-30 |
| 授权公布号 | CN116362223B |
| 授权公告日 | 2023-12-15 |
| 分类号 | G06F40/205;G06F40/154;G06F40/258;G06F40/253;G06F40/284 |
| 分类 | 计算;推算;计数; |
| 申请人名称 | 北京粉笔蓝天科技有限公司 |
| 申请人地址 | 北京市朝阳区酒仙桥北路甲10号院103号楼-1至7层101内6层601室 |
专利法律状态
2023-12-15
授权
状态信息
授权
2023-07-18
实质审查的生效
状态信息
实质审查的生效;IPC(主分类):G06F40/205;申请日:20230307
2023-06-30
公布
状态信息
公布
摘要
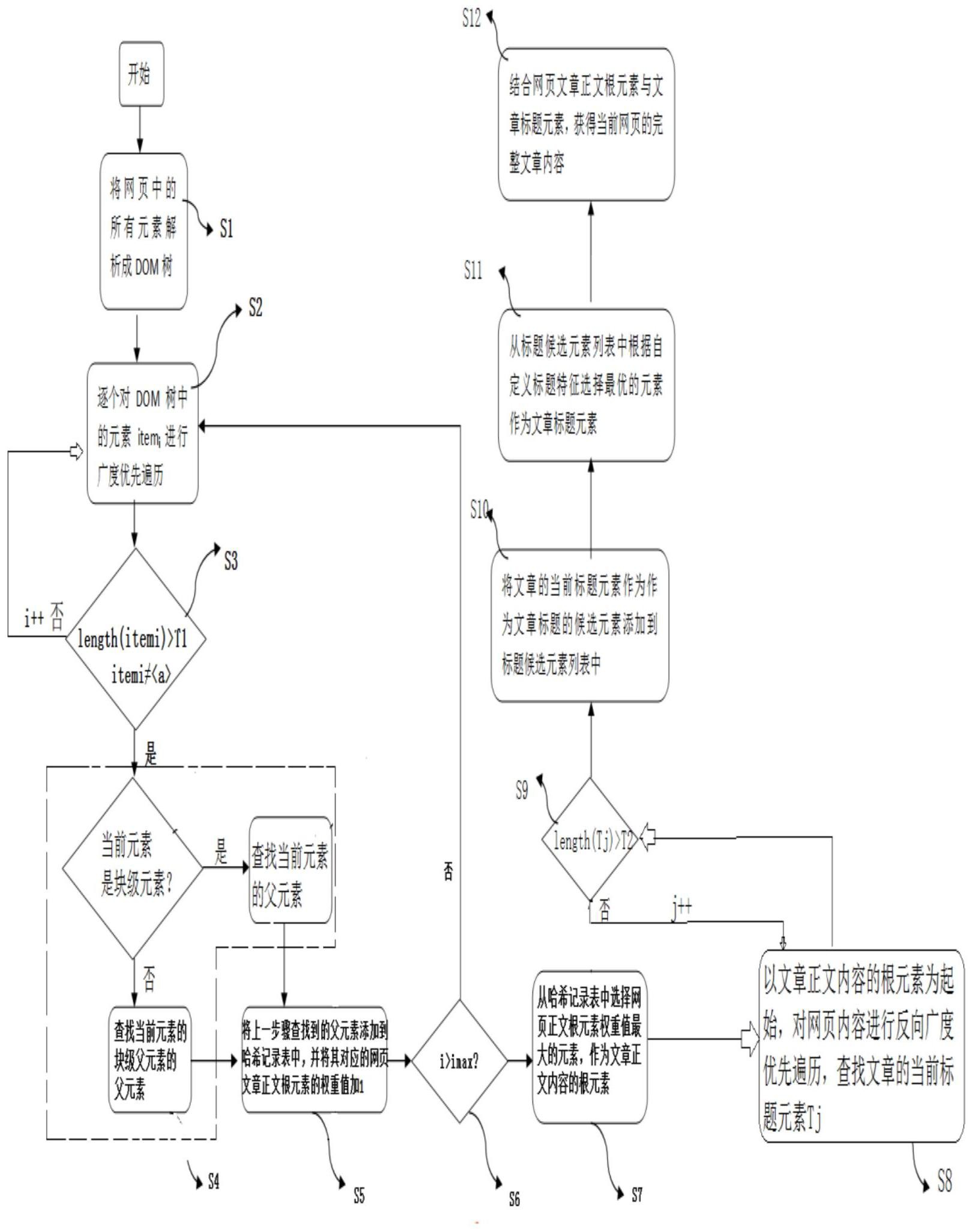
本发明提出一种网页文章标题和正文的自动识别方法及装置,属于特征识别与数据处理技术领域。方法包括将网页中的所有元素解析成DOM树、逐个对DOM树中的所有元素进行广度优先遍历、将查找到的父元素添加到哈希记录表中,并将其对应的网页文章正文根元素的权重值加1、对网页内容进行反向广度优先遍历,查找文章的当前标题元素、结合网页文章正文根元素与文章标题元素,获得当前网页的完整文章内容等步骤。本发明提出了一种在不对网页内容进行预处理的情况下,可以方便提取网页文章信息的技术方案,可以精确获取到文章的标题和正文,对下一步的数据分析和训练提供了良好的半结构化数据。
 chinappkf
客服微信号
chinappkf
客服微信号
 chinappsw
商务合作
chinappsw
商务合作
 品牌风云榜
关注公众号
品牌风云榜
关注公众号
CopyRight 2005-2026 品牌网 chinapp.com 版权所有