



新品推荐 开发人员释疑:现在的AlphaGo要比去年版本强多少
搜索
围棋
网络
sh
 2017-06-22
12:42:18
2017-06-22
12:42:18
 1257
阅读
1257
阅读
2017-06-22
12:42:18
1257
阅读
导读:5月24日消息,围棋峰会进入第二天,在今日举行的人工智能高峰论坛上,Deepmind首席程序员席尔瓦解释为何选择围棋做切入点,“围棋是人类历史上最古老,研究最深入的游戏。它是构建和理解运算的最佳试验台。人工智能面临的巨大挑战:游戏大致可以进行穷举搜索。”席尔瓦称训练AlphaGo时,通过人类专家进行监督式学习,再通过策略网络实现强化学习输入价值网络。AlphaGo树搜索通过策略网络减少
5月24日消息,围棋峰会进入第二天,在今日举行的人工智能高峰论坛上,Deepmind首席程序员席尔瓦解释为何选择围棋做切入点,“围棋是人类历史上最古老,研究最深入的游戏。它是构建和理解运算的最佳试验台。人工智能面临的巨大挑战:游戏大致可以进行穷举搜索。”
席尔瓦称训练AlphaGo时,通过人类专家进行监督式学习,再通过策略网络实现强化学习输入价值网络。AlphaGo树搜索通过策略网络减少搜索的宽度,以价值网络减少搜索的深度。
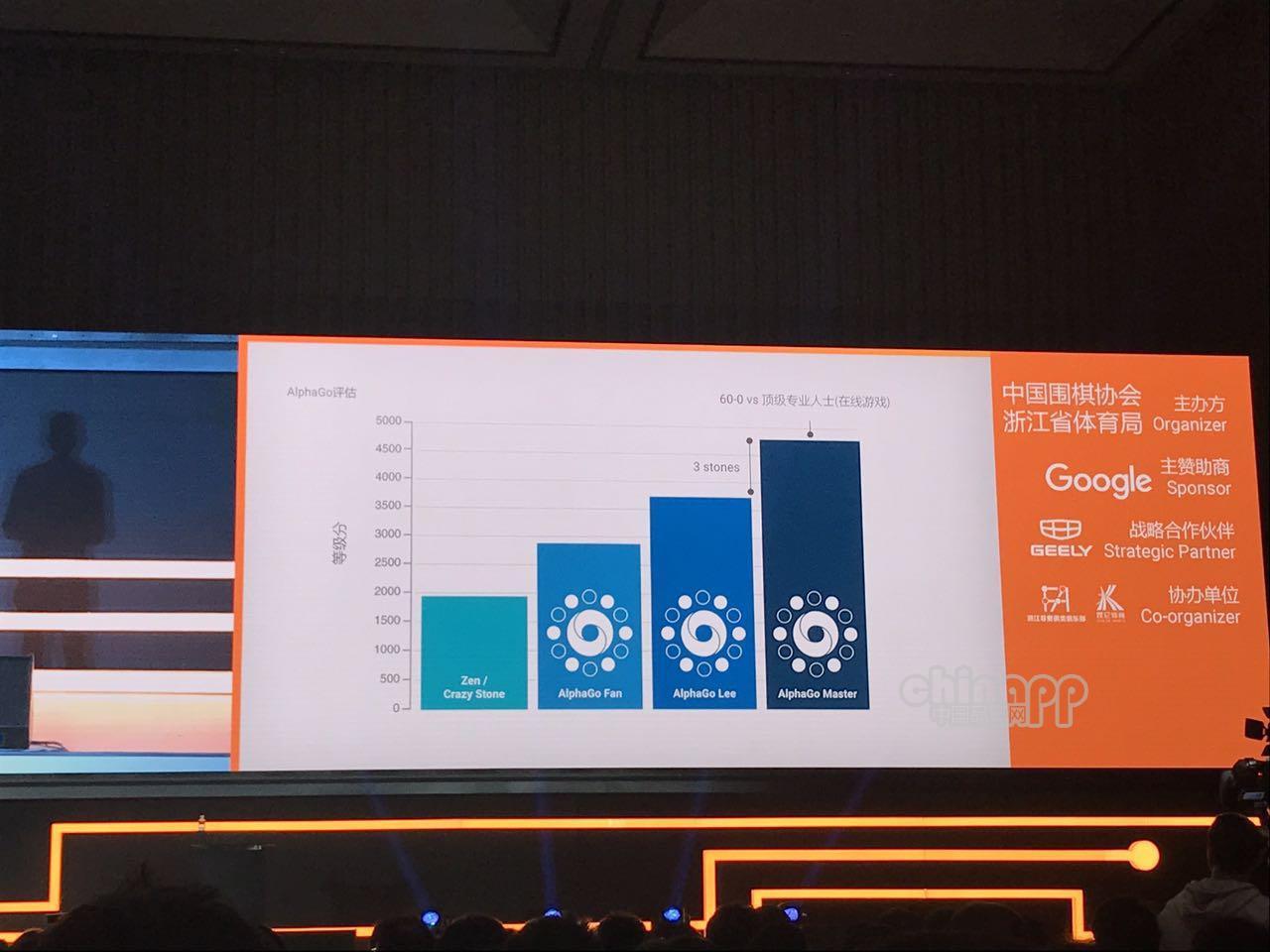
与李世石对战的AlphaGo Lee在谷歌云上有50个TPUs在运作,搜索50个棋步为10000个位置/秒,而昨天打败柯洁的AlphaGo Master则在单个TPU上进行游戏,AlphaGo成为自己的老师,它从自己的搜索里学习,有着更强大的策略和价值网络。AlphaGo Master比AlphaGo Lee强三个子(有说法是职业九段和职业初段之间的差距是让三子)。
显示全部内容...
相关动态




优秀品牌推荐









 关注微信公众号
关注微信公众号 商务合作微信
商务合作微信
CopyRight 2005-2024 品牌网
m.chinapp.com 版权所有 品牌网
m.chinapp.com 版权所有 品牌网




